Quick Start
1
Add the Ask AI node to your workflow
Drag the Ask AI node from the node library into your canvas
2
Write your prompt
Enter clear, detailed instructions in the prompt field to guide the AI
3
Choose your AI model
Select the model that best fits your task complexity and budget
4
Connect and run
Connect inputs from other nodes by dragging output badges into your prompt
Node Configuration
Required Fields
Prompt
Prompt
The main instruction or question for the AI. Your prompt should be clear and detailed to get the best possible response.Example prompt formats:
More Options
Choose AI Model
Choose AI Model
Select from over 20 AI models including Claude, GPT, Gemini, and specialized reasoning models. See AI Model Selection Guide below for detailed recommendations.
Temperature (0-1)
Temperature (0-1)
Controls response creativity and consistency.
- 0: More focused and consistent responses
- 1 (default): More creative and varied outputs
Maximum Tokens
Maximum Tokens
Limits the total response length. Sets the upper bound for how long the AI’s response can be.
For Claude models with Extended Thinking enabled, this must be greater than your Thinking Tokens setting.
Cache Response
Cache Response
Saves responses for reuse when inputs remain constant.Caching works when ALL of these are identical:
- Prompt text (including any inserted input badges)
- Model selection
- Temperature setting
- Maximum tokens
- Thinking tokens (if applicable)
Thinking Tokens (Claude Extended Thinking only)
Thinking Tokens (Claude Extended Thinking only)
Sets a budget for the model’s internal reasoning process before generating the final response.Requirements:
- Minimum: 1,024 tokens
- Must be less than Maximum Tokens
- Recommended: 4,000-16,000 for complex tasks
MCP Server Connection
MCP Server Connection
Connect to a remote Model Context Protocol (MCP) server to extend the AI’s capabilities with custom tools and data sources.
Learn how to set up and use MCP servers with the Ask AI node in the Custom MCP Servers documentation.
AI Model Fallback
Under Show More Options, configure automatic fallback when your selected AI model is unavailable. Fallback is enabled by default.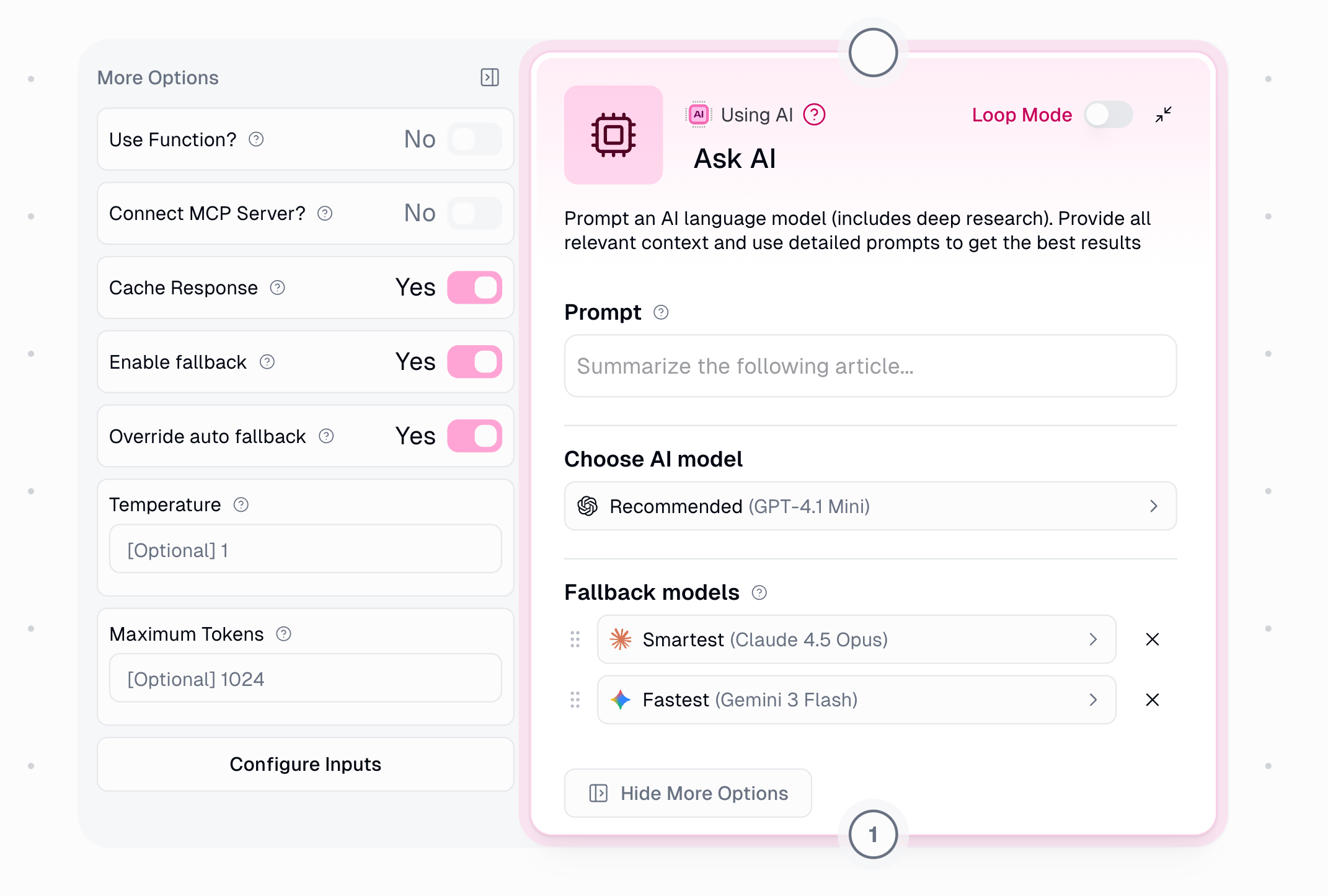
Default (Auto): The system automatically selects fallback models based on your primary model, always choosing from different providers for true redundancy.
Override: Enable to manually select up to 2 fallback models with drag-and-drop priority.
Dynamic Inputs (Show As Input)
You can configure certain parameters as dynamic inputs that can be set by previous nodes in your workflow:When enabled as inputs, these parameters can be dynamically set by previous nodes. If not enabled, the values set in the node configuration will be used.
Using Connected Node Data
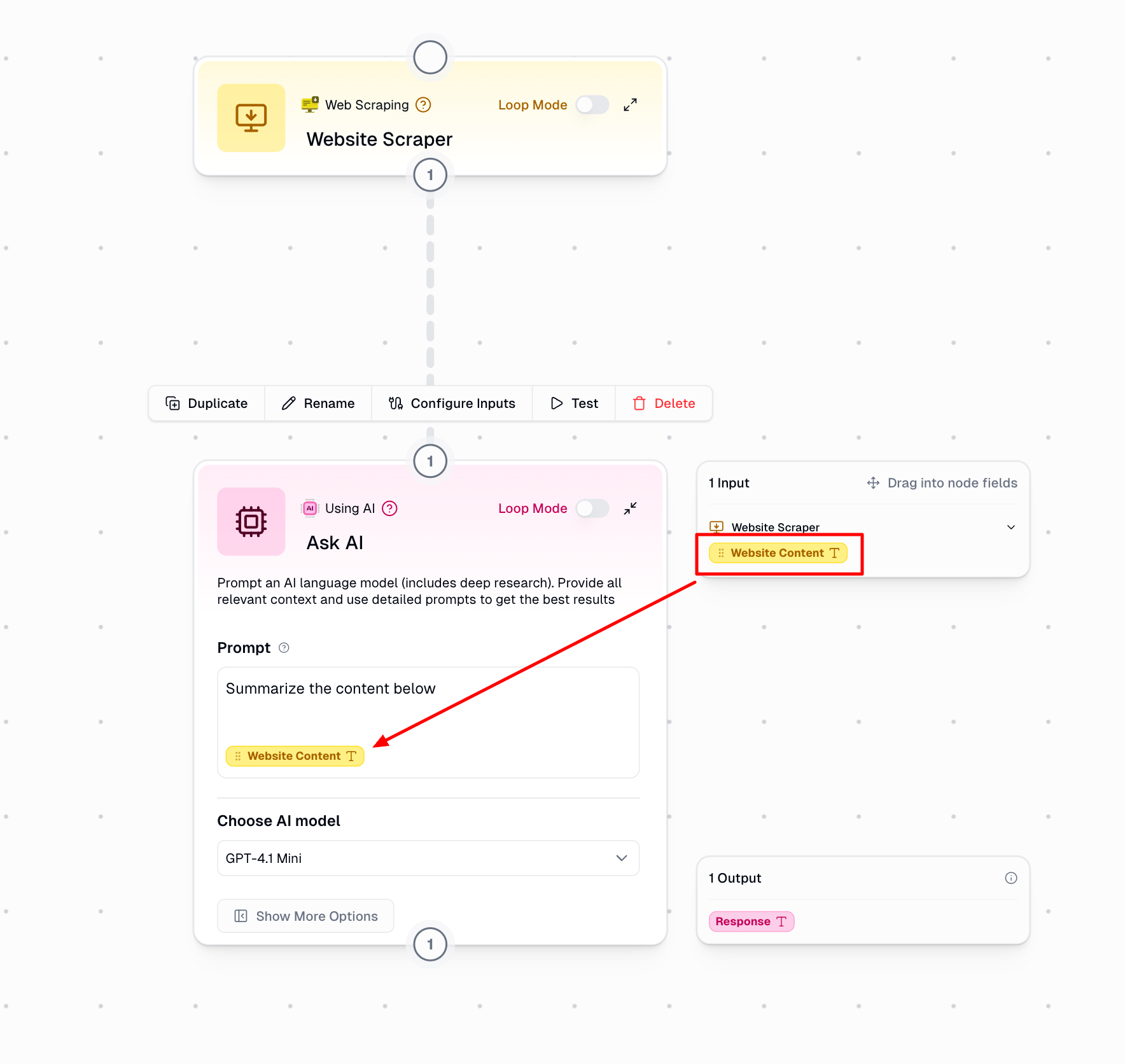
1
Connect your nodes
Drag a connection line between the source node and your Ask AI node
2
Access outputs in the side menu
Available outputs from connected nodes appear automatically in the side menu
3
Drag outputs into your prompt
Simply drag the output badge from the side menu and drop it into your prompt field
4
Format around dynamic values
Add text before and after the output badges to create well-structured prompts
Available AI Models
Gumloop supports 30+ AI models across multiple providers. Pick the model that fits your task in the node’s model dropdown, and see AI Models for the full list. Auto-Select (third-party routing that picks a model by cost and performance) and Azure OpenAI (with your own credentials) are also available.Deep Research Models
Perplexity Sonar Deep Research
Comprehensive deep research capabilities with real-time web access for demanding analytical tasks.
Deep Research models perform comprehensive, multi-step reasoning and investigation. They’re specifically designed for queries that require thorough research, fact-checking, and synthesizing information from multiple angles.
AI Model Selection Guide
Balance quality, speed, and cost when choosing a model:- Smaller, faster models cost less per token and respond quicker, which suits everyday tasks like classification, short answers, and simple analysis.
- Larger frontier models deliver higher quality on complex reasoning, coding, and detailed or long-form analysis, at a higher cost and slower response.
When to Use Deep Research Models
Deep Research models are designed for tasks that require comprehensive investigation and analysis:- Ideal For
- Not Ideal For
- How It Works
Perfect use cases for Deep Research:
- Market Research: Analyzing industry trends, competitor landscapes, and market opportunities
- Due Diligence: Investigating companies, technologies, or business proposals
- Fact-Checking: Verifying claims across multiple sources and perspectives
- Literature Review: Synthesizing information from multiple documents or sources
- Competitive Analysis: Deep comparison of products, services, or strategies
- Complex Report Generation: Creating comprehensive reports that require thorough investigation
- Multi-Perspective Analysis: Examining topics from different angles and viewpoints
Deep Research Model Comparison
Perplexity Sonar Deep Research
Best for: Comprehensive research tasks
- Real-time web access for up-to-date information
- Multi-step investigation and synthesis
- Best for research requiring current data
- Longer processing time
Additional Selection Factors
Consider these factors when choosing a model:- Task complexity and required accuracy
- Response time requirements
- Cost considerations
- Consistency needs across runs
- Specialized knowledge requirements
- Need for comprehensive investigation vs. quick answers
Node Output
Response: The AI’s generated answer or output based on your prompt and configured parameters.Common Use Cases
Content Creation
Content Creation
Data Analysis
Data Analysis
Customer Support
Customer Support
Research & Investigation (with Deep Research)
Research & Investigation (with Deep Research)
Loop Mode Pattern
When processing multiple items in Loop Mode, the Ask AI node analyzes each item individually:In Loop Mode, your workflow runs once for each item in the input list, allowing batch processing of multiple documents, queries, or data points.
Credit Costs
The Ask AI node is billed by token usage, the same way agents are. The cost of a run depends on the model you pick and how many input and output tokens it uses, so a short prompt costs far less than a long-context one. There are no fixed per-run tiers.- Smaller, faster models cost less per token than frontier models. See AI Models.
- Keeping your prompt and inputs lean lowers the cost.
Important Considerations
Function Calling
Function Calling
The ‘Use Function’ option enables structured output formatting and is only available for OpenAI models.
Learn more in the OpenAI Function Calling Documentation.
Model Selection Strategy
Model Selection Strategy
Consider task complexity when selecting models. For reasoning-heavy tasks, consider thinking-enabled or specialized reasoning models. For straightforward content generation, standard models are often sufficient and more cost-effective.
Working with Connected Nodes
Working with Connected Nodes
- Drag output badges from the side menu directly into your prompt
- Format text around badges for better prompting
- All outputs from connected nodes appear in the side menu
- No need for separate Combine Text nodes
Multimodal Content
Multimodal Content
The Ask AI node is text-based only:
- To analyze images, use the Analyze Image node
- To create images, use the Generate Image node
The Ask AI node is your interface to leading AI models, helping you automate text processing and generation tasks with customizable control over output style and format. With Gumloop’s improved UI, you can easily incorporate data from connected nodes directly into your prompts, creating powerful automated workflows without complex configuration.