What is a List Size Mismatch Error?
A list size mismatch error happens when a node receives multiple list inputs of different lengths. In Gumloop, when a node processes multiple list inputs together (eg in Loop Mode), the lists must be the same size so the node knows how to pair up the items. Let’s look at a simple example using aCombine Text node:
- A list of 5 company names from a Google Sheet
- A list of 2 company URLs from an Airtable
Why Do List Size Mismatches Occur?
Let’s explore the two main scenarios where list size mismatches typically occur, using a real example workflow that processes company data. You can follow along with the example workflow here.1. Direct Source vs Processed Data
This scenario occurs when:- One input comes directly from a source (like a Google Sheet)
- Another input goes through processing that may filter or skip items
- The processed list ends up shorter than the source list
- Reading company URLs from a Google Sheet
- Filtering invalid URLs
- Scraping and summarizing company information
- Combining the original company name with its description
Note: One of the inputs is not a valid URLWhen we run this workflow, we encounter a list size mismatch:
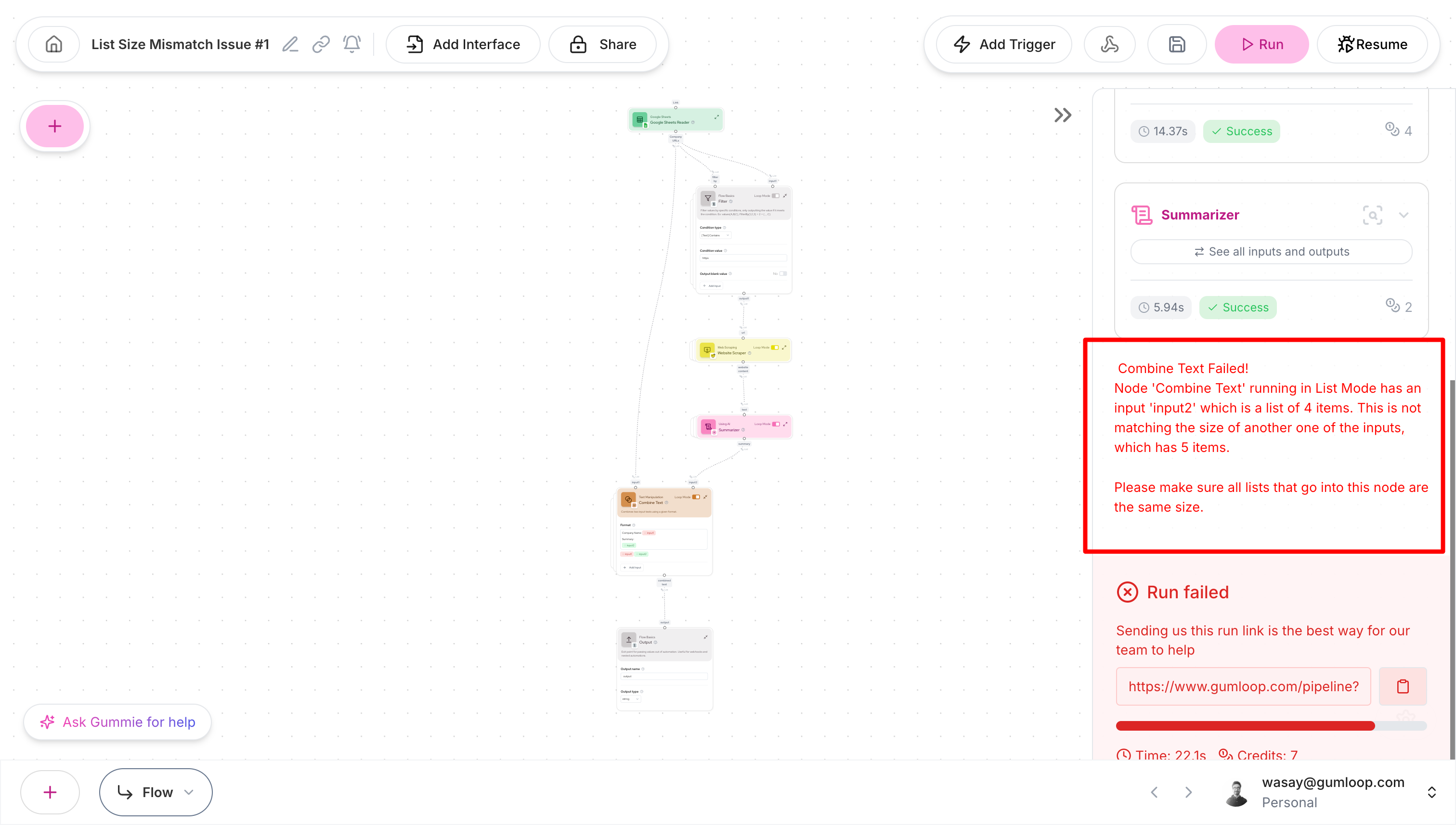
- The company names come directly from the Google Sheet (5 items)
- The descriptions come from filtered and processed data (4 items, one was invalid)
- The
Combine Textnode can’t match these different-sized lists
2. Error Shield Effects
A similar mismatch occurs with Error Shield:- When Error Shield wraps around nodes processing list items
- Failed items are skipped, reducing the output list size
- Other inputs retain their original size
Using Subflows to Resolve List Size Mismatch Errors
The solution to these list size mismatches is proper workflow organization using subflows. Let’s see how we can fix our example workflow. View the corrected workflow here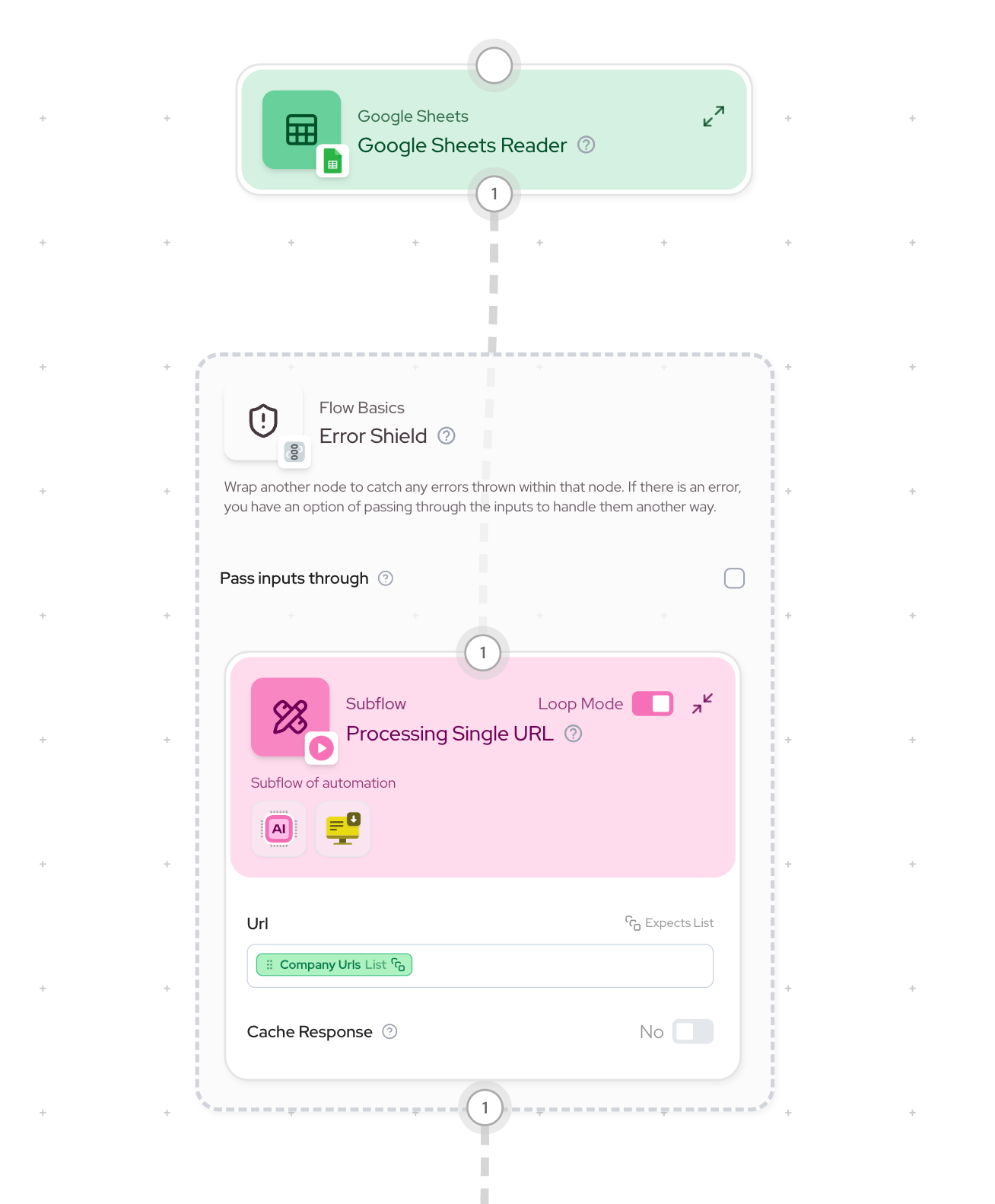
- Related operations (scraping, summarizing, text combination) are grouped in a subflow
- Error Shield wraps the entire subflow
- Failed items are handled consistently throughout the process
- All related operations for that item are skipped
- List sizes stay matched throughout the workflow
- Error handling is consistent and predictable
Error Shield Placement
The key to resolving list size mismatches is understanding how Subflows & Error Shield affects your data when it’s placed in different locations. Let’s see why Error Shield works better around a subflow than around individual nodes.The Problem: Error Shield Around Individual Nodes
Let’s look at a typical workflow: When Error Shield is around just the Website Scraper:- The scraper fails for 2 URLs
- Error Shield removes those 2 items from the scraper’s output
- But the company names list hasn’t been filtered
- Result: List size mismatch (3 scraped URLs vs 5 company names)
The Solution: Error Shield Around Subflow
Here’s the better approach: When Error Shield wraps a subflow:- If the scraper fails for 2 URLs
- Error Shield removes those items from ALL operations in the subflow
- Both the scraped content AND company names are removed for failed items
- Result: Lists stay matched (both have 3 items)