Join Paths eliminates the need for duplicate nodes by merging the paths back together.
Overview
Think of Join Paths as a merge point in your workflow. After your workflow splits into different branches based on conditions, Join Paths brings the active branch back to continue processing through the same set of nodes.Eliminate Duplicate Nodes
No need to repeat the same nodes in each conditional branch
Cleaner Workflows
Maintain single processing paths after conditions
Better Maintenance
Update one set of nodes instead of multiple copies
Resource Efficiency
Reduce redundant operations and simplify logic
How It Works
Join Paths takes multiple input connections but only one path is active during runtime. The active path (determined by your conditional logic) workflows through Join Paths and continues to the next node.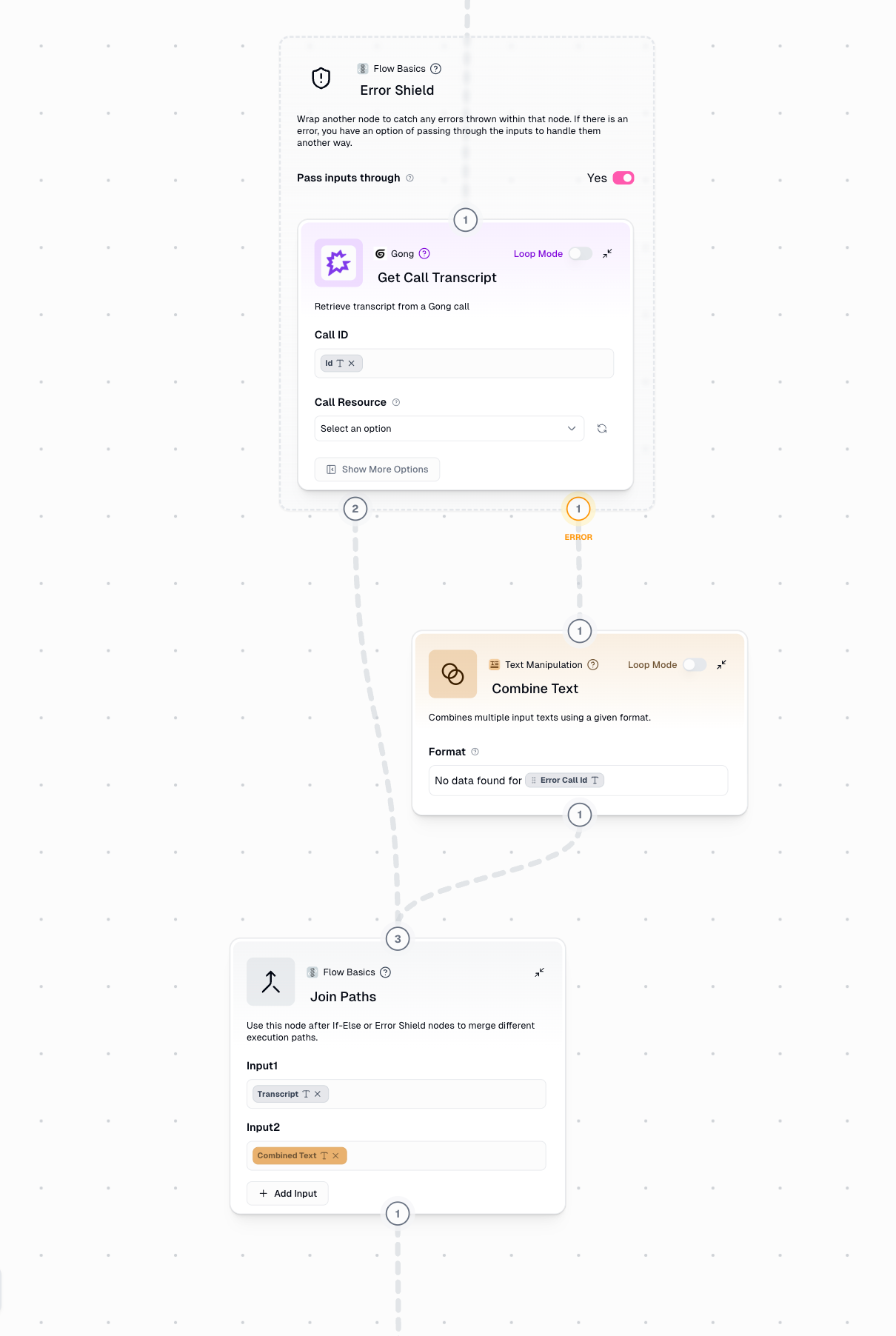
Configuration
Input 1 (Required)
Input 1 (Required)
Connect the first potential execution path. This can be any data type (text, list, object, etc.)
Input 2 (Required)
Input 2 (Required)
Connect the second potential execution path. Must match the data type of Input 1 to ensure consistency
Additional Inputs (Optional)
Additional Inputs (Optional)
Add more input connections for complex branching scenarios with 3+ conditional paths. Click the ”+” button to add additional inputs.Example: Processing Google Docs, PDFs, or websites requires 3 inputs on Join Paths
Output
- Continuation Path
- Pruned Paths
Data from Executed Branch: Join Paths outputs whatever data comes from the active pathType Preservation: The original data type is maintained (if Input 1 sends text, output is text)No Merging: Join Paths does NOT combine data from multiple paths - only the active path workflows through
When to Use Join Paths
If-Else / Router Conditionals
Reconnect true/false branches after conditional logic
Error Shield Patterns
Merge success and error paths to continue workflow
Why Join Paths Matters
Without Join Paths, you’re forced to duplicate nodes after every conditional split: Using Join Paths eliminates duplication by merging paths back together:Example Workflows
Example: If-Else with Join Paths
Scenario: Processing content from either Google Docs or websites Try it yourself: View and clone this example workflow1
Receive URL Input
User provides a URL that could be either a Google Doc or a regular website
2
Check Document Type
If-Else node determines if the URL is a Google Doc link
3
Extract Content Appropriately
- True path: Use Google Docs integration to extract content
- False path: Use Website Scraper to get content
4
Merge Paths
Join Paths combines both extraction methods into a single continuation point
5
Process Uniformly
Single Summarize node handles content from either source
Without Join Paths, you’d need two separate Summarize nodes - one after the Google Doc extraction and one after the website scraping. With Join Paths, you only maintain one Summarize node.
Example: Error Shield with Join Paths
Scenario: Web scraping with error handling and result logging Try it yourself: View and clone this example workflow1
Protect Scraping Operation
Wrap Website Scraper in Error Shield to catch failures
2
Handle Success Path
Successfully scraped content workflows directly to Join Paths
3
Handle Error Path
Failed scrapes trigger error path, which creates a fallback message like “Site Unavailable”
4
Merge Results
Join Paths ensures both successful scrapes and error messages continue to the next step
5
Log All Results
Single “Write to Sheet” node logs both successful and failed attempts
Example: Multi-Source Content Processor
Scenario: Handling different document types (Google Docs, PDFs, websites) Try it yourself: View and clone this example workflow1
First Conditional Check
Check if input is a Google Doc URL
2
Second Conditional Check
If not a Google Doc, check if it’s a PDF
3
Three Processing Paths
- Google Doc: Use Docs integration
- PDF: Use PDF extraction
- Website: Use web scraper
4
Merge All Paths
Join Paths with 3 inputs consolidates all document types
5
Unified Processing
Single Summarize node processes content regardless of original format
Note: When using multiple conditional checks, add additional inputs to Join Paths by clicking the ”+” button. This example requires 3 input connections.
Loop Mode Limitations
Why No Loop Mode?
Join Paths is designed for single-path execution where only one branch is active at a time. Loop Mode processes multiple items concurrently, which would create ambiguity:- Which path’s data should continue when multiple branches are active simultaneously?
- How should Join Paths handle item 1 taking the success path while item 2 takes the error path?
- What happens to synchronization between different loop iterations?
Solution: Use Subflows
If you need to process multiple items with conditional logic:1
Create a Subflow
Build your conditional logic and Join Paths inside a subflow that handles a single item
2
Test with Single Input
Verify the subflow works correctly with one item
3
Enable Loop Mode on Subflow
In your main workflow, enable Loop Mode on the subflow node itself (not on nodes inside the subflow)
4
Pass in List
Connect a list of items to the subflow, which will process each item through the conditional logic independently
Best Practices
Always Use After Conditional Splits
Always Use After Conditional Splits
Whenever you create a branching condition (If-Else, Error Shield, Router), consider if the paths need to reunite for common processing. If yes, use Join Paths.
Match Data Types Across Inputs
Match Data Types Across Inputs
Ensure all potential paths output the same data type to Join Paths:
- If one path outputs text, all paths should output text
- If one path outputs a list, all paths should output lists
Use for Error Shield (Non-Loop Mode)
Use for Error Shield (Non-Loop Mode)
When Error Shield wraps a node that’s NOT in Loop Mode, always use Join Paths to:
- Prevent error paths from becoming dead ends
- Allow workflow to continue after error handling
- Enable unified logging of both success and failure cases
Name Your Paths Clearly
Name Your Paths Clearly
Add clear labels to your conditional branches so you can easily identify which path data came from during debugging.
Test Each Branch Independently
Test Each Branch Independently
Before connecting Join Paths:
- Test each conditional branch separately
- Verify each path produces the expected output type
- Then connect Join Paths and test the full workflow
For Lists, Use Subflows
For Lists, Use Subflows
Don’t try to use Join Paths directly in Loop Mode. Instead:
- Create a subflow with conditional logic + Join Paths
- Use Loop Mode on the subflow itself
- Process lists efficiently while maintaining clean conditional logic
Additional Resources
Error Shield Documentation
Learn how to use Error Shield with Join Paths
Subflows Guide
Use Join Paths with Loop Mode via subflows
Router Node
Advanced multi-path routing for 3+ conditions