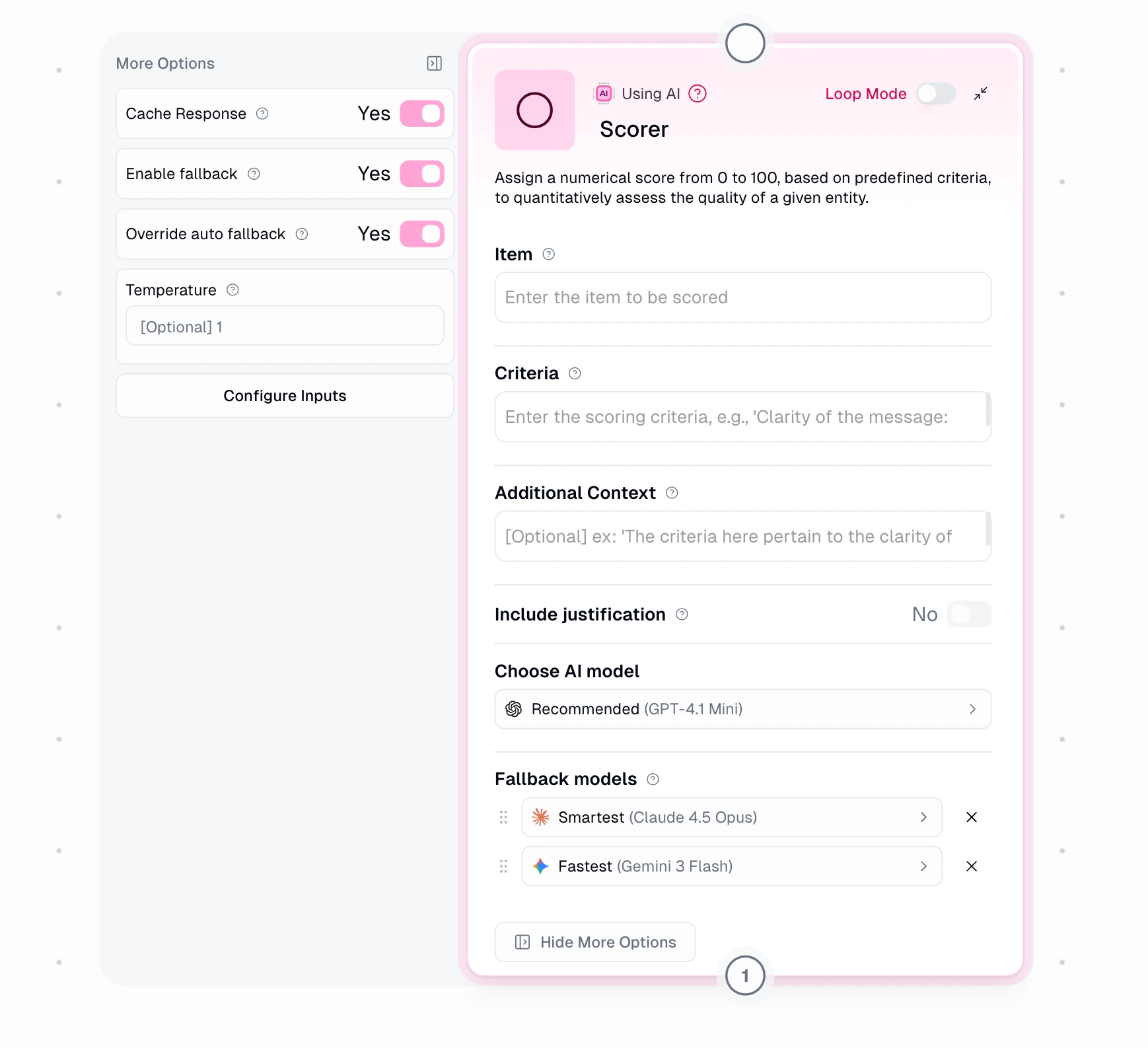
Node Inputs
Required Fields
- Item: The content to be scored
- Criteria: Rules for scoring (e.g., “Clarity: 0-30, Grammar: 0-40, Relevance: 0-30”)
Optional Fields
- Include Justification: Get AI’s reasoning for scores
- Additional Context: Extra guidance for scoring
- Temperature: Controls scoring consistency (0-1)
- 0: More focused, consistent
- 1: More creative, varied
- Cache Response: Save responses for reuse
Show As Input
The node allows you to configure certain parameters as dynamic inputs. You can enable these in the “Configure Inputs” section:-
item: String
- The text or item to be scored
- Example: “Customer feedback response”
-
criteria: String
- The scoring criteria or rubric
- Example: “Score based on clarity, politeness, and helpfulness”
-
Additional Context: String
- Extra information to help with scoring
- Example: “This is feedback from a premium customer”
-
include_justification: Boolean
- true/false to include explanation for the score
- When enabled, provides reasoning for the assigned score
-
model_preference: String
- Name of the AI model to use
- Accepted values: “Claude 4.6 Sonnet”, “Claude 4.5 Haiku”, “GPT-5.5”, “GPT-5.4”, etc.
-
Cache Response: Boolean
- true/false to enable/disable response caching
- Helps reduce API calls for identical inputs
-
Temperature: Number
- Value between 0 and 1
- Controls scoring consistency
AI Model Fallback
Under Show More Options, configure automatic fallback when your selected AI model is unavailable. Fallback is enabled by default. When an error occurs (rate limits, provider outages, timeouts), the system retries based on severity, then falls back to the next model. Fallback models are always from different providers for true redundancy.
Default (Auto): The system automatically selects fallback models based on your primary model, always choosing from different providers for true redundancy.
Override: Enable to manually select up to 2 fallback models with drag-and-drop priority.
Node Output
- Score: Numerical value between 0-100
- Justification: AI’s scoring explanation (if enabled)
Node Functionality
The Scorer node:- Analyzes content against criteria
- Assigns numerical scores
- Provides scoring rationale
- Handles batch scoring
- Ensures consistent evaluation
Available AI Models
Gumloop supports 30+ AI models across every major provider. Pick the model that fits your task in the node’s model dropdown, and see AI Models for the full list.Auto-Select uses third-party routing to choose models based on cost and performance. Not ideal when consistent behavior is required.
AI Model Selection Guide
Balance quality, speed, and cost when choosing a model:- Smaller, faster models cost less per token and respond quicker, which suits everyday tasks like classification, short answers, and simple analysis.
- Larger frontier models deliver higher quality on complex reasoning, coding, and detailed or long-form analysis, at a higher cost and slower response.
- Task complexity and required accuracy
- Response time requirements
- Cost considerations
- Consistency needs across runs
- Specialized knowledge requirements
- Anthropic Models Overview
- Anthropic Extended Thinking Documentation
- OpenAI Reasoning Guide
- OpenAI GPT-5 Models
Common Use Cases
- Content Quality:
- Support Responses:
- Product Reviews:
Loop Mode
Important Considerations
- This node is billed by token usage, the same way agents are, so the cost of a run depends on the model you pick and how many input and output tokens it uses
- Add your own provider API key on the Connectors page to run its AI calls for 50% fewer credits (Pro plan or higher)
- Define clear, measurable criteria for accurate output
- Enable justification for transparency