Overview
Think of Error Shield as a safety net for risky operations. When you wrap a node with Error Shield, it creates two possible outcomes: a success path for data that processes correctly, and an error path for handling failures.Prevent Workflow Crashes
Catch errors before they stop your entire automation
Handle Failures Gracefully
Define custom logic for errors instead of generic failure messages
Track Failed Items
Identify which specific inputs caused problems in Loop Mode
Continue Processing
Keep your workflow running even when some items fail
How It Works
Error Shield wraps around other nodes and monitors their execution. When the wrapped node processes data:- Success: Output workflows to the Success Path
- Failure: Output workflows to the Error Path (original input if “Pass Inputs Through” is enabled)
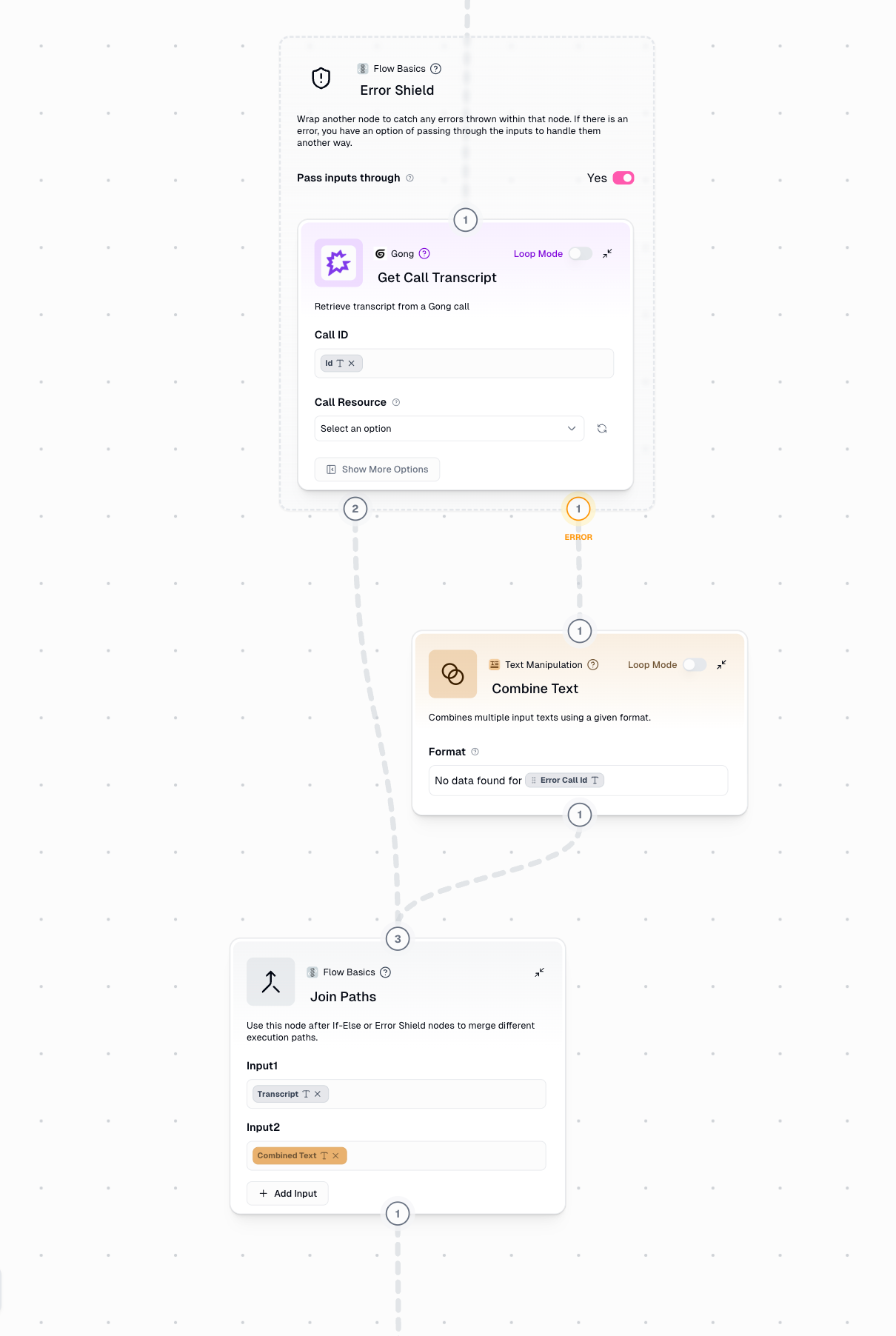
Configuration
Wrapped Node
Wrapped Node
The node you want to protect from errors. Simply drag a node inside the Error Shield container to wrap it.
Pass Inputs Through
Pass Inputs Through
When enabled, the Error Path receives the original input that caused the error instead of an error message. This is essential when you need to:
- Log which specific items failed
- Retry failed items later
- Format fallback data based on the original input
Outputs
- Success Path
- Error Path
Contains data that was successfully processed by the wrapped node.Single Item: The processed resultLoop Mode: A list containing only the successfully processed items
Critical Behavior in Loop Mode
Understanding how Error Shield behaves in Loop Mode is essential for building reliable workflows.Node NOT in Loop Mode
When the wrapped node is not in Loop Mode, Error Shield processes a single item at a time: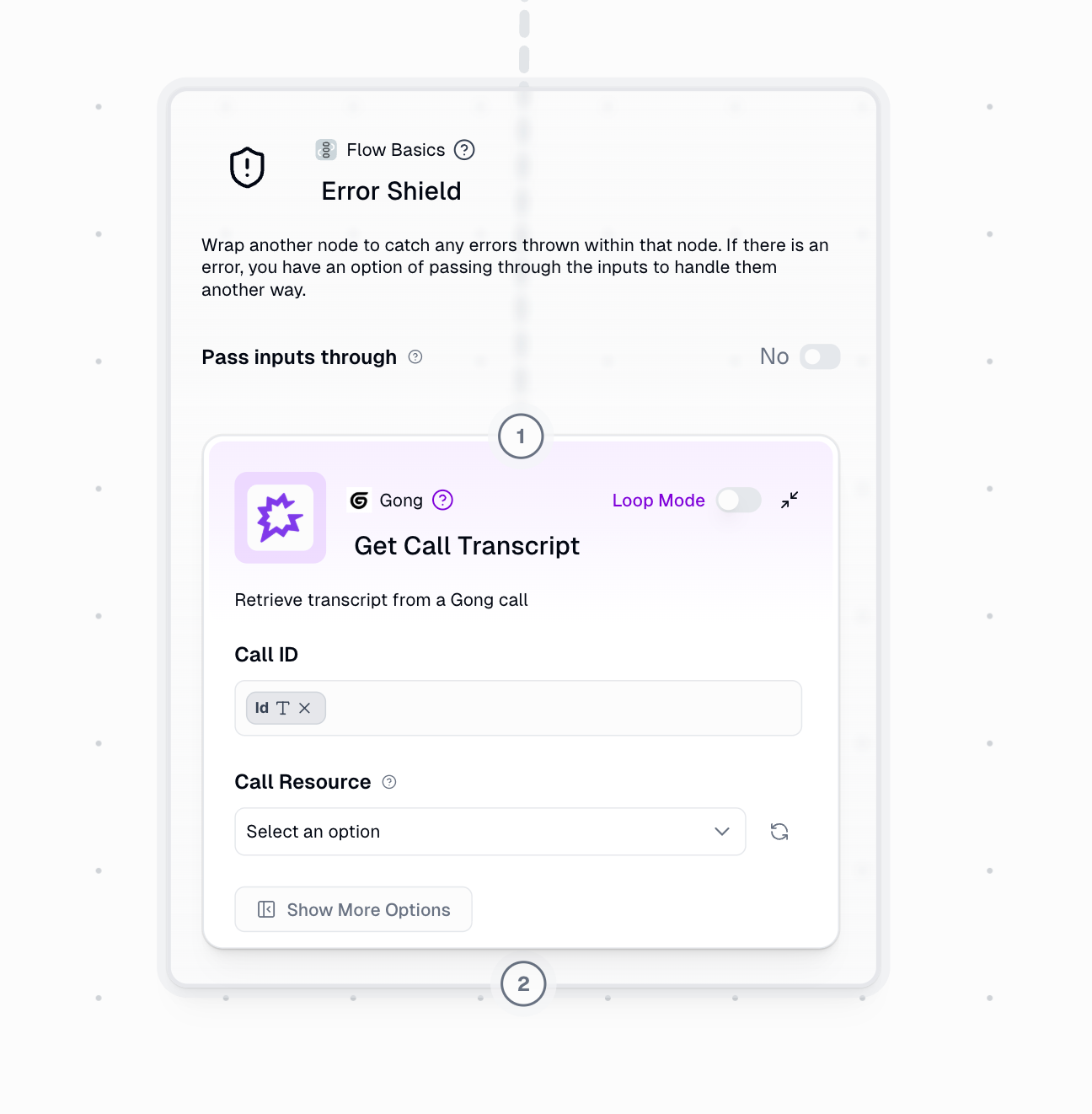
Node in Loop Mode
When the wrapped node is in Loop Mode, Error Shield processes each item individually and continues even when some items fail: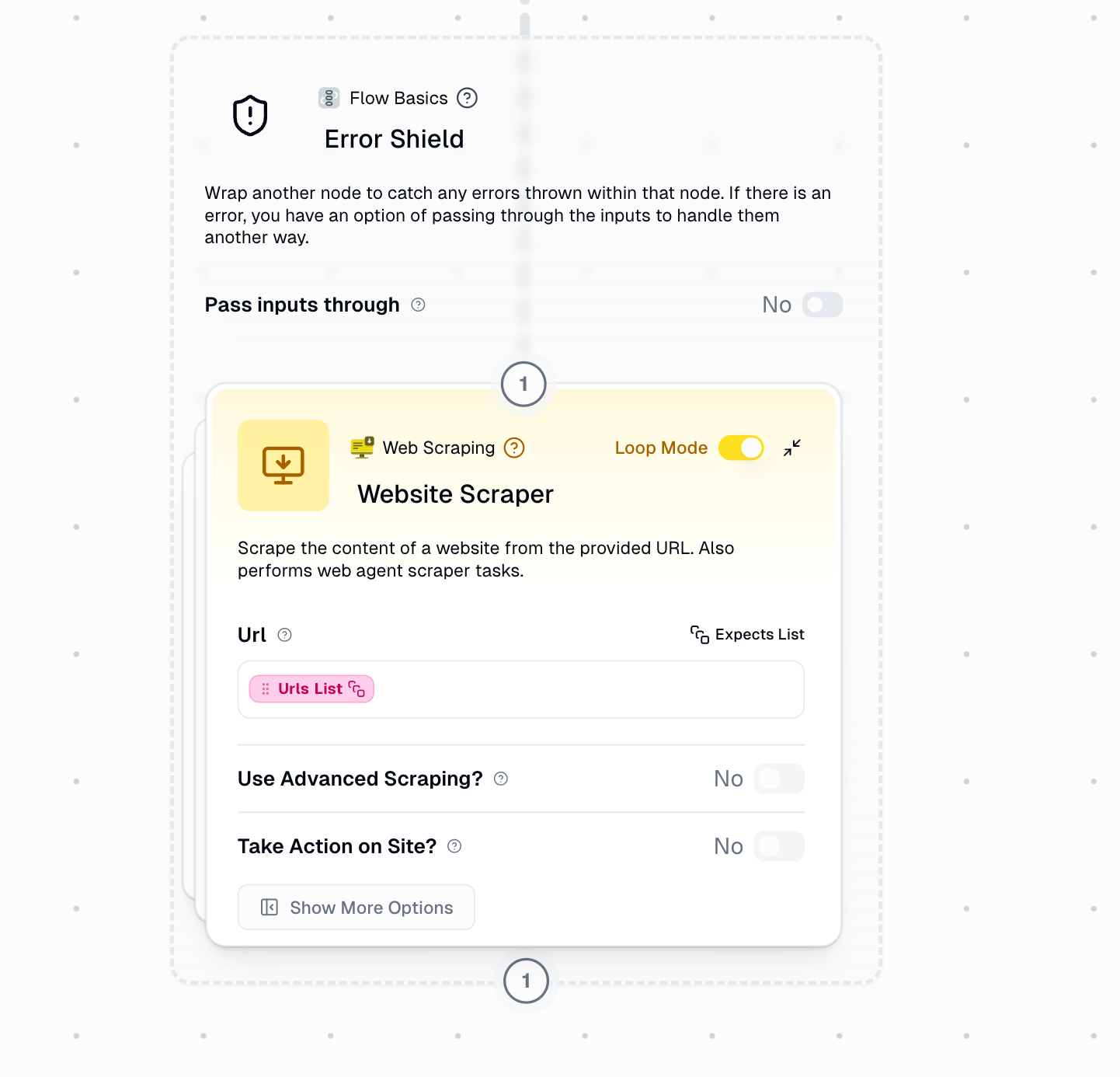
Working with Join Paths
To continue your workflow after handling errors, use the Join Paths node to merge success and error paths back together.Basic Pattern: Single Item Processing
When processing individual items (not in Loop Mode), you need Join Paths to continue the workflow after an error:1
Enable Pass Inputs Through
Turn on “Pass Inputs Through” in Error Shield to access the original input on the error path
2
Format Fallback Data
On the error path, create fallback data or a message indicating the failureExample: Use Combine Text to create “Failed to process: [original input]”
3
Join the Paths
Connect both success and error paths to a Join Paths node to reunite them
4
Continue Workflow
After Join Paths, continue with the rest of your workflow logic
Without Join Paths, the error path would be a dead end, and your workflow would stop when an error occurs.
Real-World Examples
Web Scraping with Error Handling
Web Scraping with Error Handling
Scenario: Scrape product information from multiple websites, some of which may be down or blocked.Setup:
- List of product URLs → Website Scraper (Loop Mode) wrapped in Error Shield
- Success Path → Extract product details → Format as JSON
- Error Path (Pass Inputs Through enabled) → Log failed URLs to sheet
- Join Paths → Send summary email with results and failed URLs
Document Processing with Fallback
Document Processing with Fallback
Scenario: Process invoices from various sources, providing default values when extraction fails.Setup:
- Invoice PDF → Extract data (wrapped in Error Shield)
- Success Path → Format extracted data
- Error Path → Create record with “Manual review required” status
- Join Paths → Save to database
API Calls with Retry Logic
API Calls with Retry Logic
Scenario: Fetch user data from external API that occasionally times out.Setup:
- User ID → API call (wrapped in Error Shield)
- Success Path → Process user data
- Error Path → Wait 30 seconds → Retry API call (wrapped in second Error Shield)
- Second Success Path → Process user data
- Second Error Path → Log failure and notify admin
- Join Paths → Continue workflow
Batch Email Sending
Batch Email Sending
Scenario: Send personalized emails to customer list, tracking delivery failures.Setup:
- Customer list → Send Email node (Loop Mode) wrapped in Error Shield
- Success Path → Log successful sends to “Delivered” sheet
- Error Path (Pass Inputs Through) → Log failed emails to “Bounced” sheet with customer details
- Join Paths → Generate summary report
Common Use Cases
Web Scraping
Handle website timeouts, blocks, or invalid URLs without stopping your entire scraping job
File Processing
Continue processing a batch of files even if some are corrupted or in unexpected formats
API Integrations
Manage rate limits, timeouts, and invalid responses from external services
Data Validation
Process valid records while capturing and handling invalid ones separately
Setup Guide
1
Add Error Shield to Canvas
Drag the Error Shield node from the Workflow Basics section onto your workflow canvas
2
Wrap Your Node
Place the node you want to protect inside the Error Shield container. The node will now be protected from errors.
3
Enable Pass Inputs Through (Optional)
Toggle this setting if you need to access the original input that caused errors. This is essential for:
- Logging which specific items failed
- Creating fallback data based on original input
- Retrying failed operations
4
Connect Success Path
Wire the Success Path output to the next step in your workflow that should receive successfully processed data
5
Handle Error Path
Connect the Error Path to error handling logic:
- Log failures to a database or sheet
- Send notification alerts
- Create fallback data
- Format error messages for users
6
Use Join Paths (If Needed)
If both paths need to continue through the same workflow logic, add a Join Paths node to merge them back together
7
Test Both Paths
Run your workflow with both valid and invalid inputs to ensure both success and error paths work as expected
Best Practices
Always Use with Risky Operations
Always Use with Risky Operations
Wrap any node that might fail in Error Shield:
- External API calls
- Web scraping
- File operations
- Database queries
- Email sending
- Data transformations on uncertain input formats
Enable Pass Inputs Through for Loop Mode
Enable Pass Inputs Through for Loop Mode
When processing lists, always enable “Pass Inputs Through” so you can track which specific items failed and potentially retry them later.
Use Join Paths for Non-Loop Workflows
Use Join Paths for Non-Loop Workflows
If the wrapped node is NOT in Loop Mode, use Join Paths to allow your workflow to continue after error handling. Without it, errors create dead ends in your workflow.
Consider Using Subflows
Consider Using Subflows
For complex error handling in Loop Mode, wrap your entire processing logic in a subflow, then wrap the subflow in Error Shield. This keeps related data together and prevents list size mismatches.Learn more about Subflows with Error Shield
Additional Resources
Video Tutorial
Watch a step-by-step guide to using Error Shield
Join Paths Documentation
Learn how to merge conditional paths
Loop Mode Guide
Understand how Loop Mode processes lists
List Size Mismatch Errors
Fix common errors with Error Shield and Loop Mode