Quick Overview
Base Cost
1 credit for basic scraping
Web Agent Mode
10 credits for interactive actions
Loop Mode
Fully supported for batch processing
Output Format
Plain text content & URLs
Two Modes of Operation
- Basic Scraping (1 credit)
- Web Agent Mode (10 credits)
What it does:
- Extracts readable text from web pages
- Handles static HTML content
- Processes standard websites efficiently
- Blog posts and articles
- Public web pages
- Simple data extraction
- Cost-sensitive projects
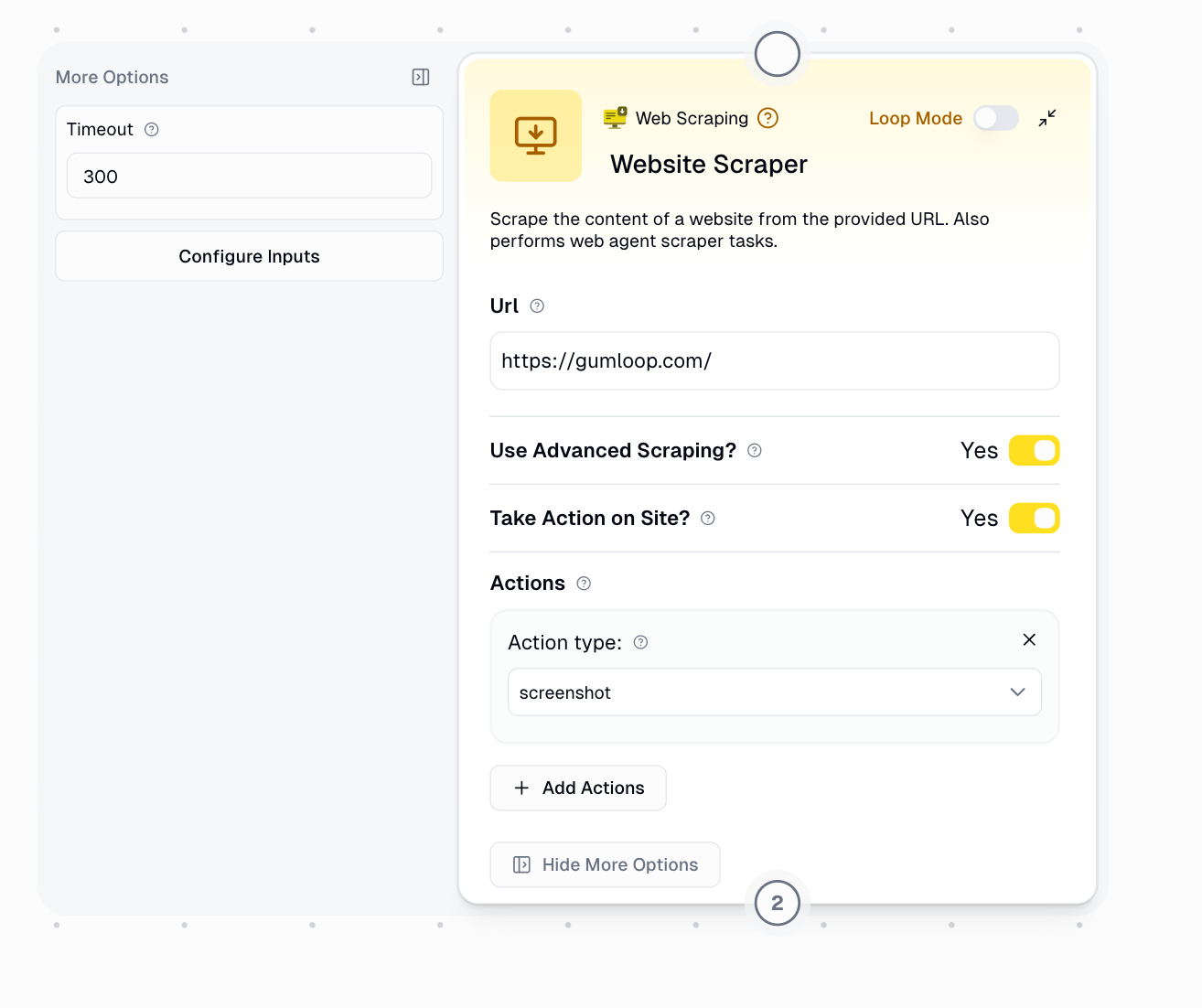
Configuration
Required Input
URL (String)- The web address you want to scrape or interact with
- Example:
https://www.gumloop.com/
Optional Parameters
Take Action on Site?
Take Action on Site?
Purpose: Enables interactive browser automation (Web Agent mode)When to enable:
- Content requires clicking, scrolling, or typing
- Need to navigate through multi-step processes
- Want to take screenshots
- Must interact with dynamic elements
- Actions parameter (configure browser interactions)
- Scraped URL output (get the final URL after actions)
Actions
Actions
Availability: Only appears when “Take Action on Site?” is enabledPurpose: Define a sequence of actions for the browser agent to performAvailable Actions:
- click - Click on an element
- hover - Hover over an element
- scroll - Scroll the page
- write - Type text into a field
- wait - Pause for a specified duration
- screenshot - Capture visible area
- screenshot - full page - Capture entire page
- screenshot - full page mobile - Capture full page in mobile view
- scrape - Extract content
- scrape raw HTML - Get raw HTML
- get url - Get current URL
- get all urls - Extract all URLs on page
- get link by label - Find link by its text
Use Advanced Scraping?
Use Advanced Scraping?
Purpose: Uses residential proxies for better access to restricted sitesWhen to enable:
- Website blocks standard scrapers
- Experiencing rate limiting or IP blocks
- Need higher reliability on protected sites
- Basic mode: +1 credit (total: 2 credits)
- Web Agent mode: +10 credits (total: 20 credits)
Timeout
Timeout
Purpose: Maximum wait time (in seconds) before considering the request failedDefault: 300 seconds (5 minutes)When to adjust:
- Increase for complex multi-step processes or very slow sites
- Decrease if you want faster failure detection
60 for a 1-minute timeoutOutput
- Website Content
- Scraped URL
Always available in both modesReturns the scraped text content from the webpage, including:✅ Main text content and article body
✅ Readable elements and structured data
✅ Clean text extraction❌ Excludes JavaScript code, CSS styling, and hidden elements
✅ Readable elements and structured data
✅ Clean text extraction❌ Excludes JavaScript code, CSS styling, and hidden elements
Common Use Cases
- Basic Content Extraction
- Interactive Scraping
- Screenshot Capture
- Lead Enrichment
Scenario: Research industry trendsWorkflow:Configuration:
- Take Action: Disabled
- Advanced Scraping: Disabled
Using Loop Mode
Process multiple URLs efficiently with Loop Mode for batch scraping or automation.Provide a list of URLs
Input an array of URLs instead of a single URL
Configure your scraping mode
Choose between:
- Basic scraping (1 credit each) for simple content extraction
- Web Agent mode (10 credits each) for interactive tasks
Understand concurrency limits
Your plan determines parallel processing capacity:
Handle results
The node returns arrays of results, maintaining input order:
- Array of Website Content (one per URL)
- Array of Scraped URLs (if Take Action enabled)
Integration Patterns
Search + Scrape
Web Search → Website ScraperFind relevant pages, then extract their contentScrape + Extract
Website Scraper → Extract Data (AI)Scrape content, then extract structured information with AIAgent + Analysis
Website Scraper (Agent) → Ask AIPerform interactions, then analyze the resultsBatch + Storage
Sheets Reader → Website Scraper (Loop) → Sheets WriterRead URLs from spreadsheet, scrape all, save resultsBest Practices
Choosing Between Basic and Web Agent Mode
Choosing Between Basic and Web Agent Mode
Use Basic Mode (1 credit) when:
- Scraping static HTML pages
- Content is immediately available
- No user interaction required
- Cost efficiency is important
- Content loads dynamically via JavaScript
- Need to click, type, or navigate
- Taking screenshots
- Extracting URLs after interactions
URL Validation
URL Validation
- Always ensure URLs include
https://orhttp:// - Use Text Formatter to add protocol if missing
- Filter out empty or invalid URLs before scraping
- Test with a single URL before running large batches
Error Handling
Error Handling
- Wrap Website Scraper in Error Shield for production workflows
- Especially critical in Loop Mode where one failure can affect all results
- Plan alternate logic paths for failed scrapes
- Monitor workflow history to identify problematic URLs
Action Sequence Design
Action Sequence Design
When using Web Agent mode:
- Always end with a scraping or URL action to get usable output
- Add wait actions after clicks to allow content to load
- Use hover before click if dropdown menus are involved
- Test action sequences with single URLs first
Cost Optimization
Cost Optimization
- Use basic scraping whenever possible (1 credit vs 10)
- Only enable Advanced Scraping when you encounter blocking issues
- Test without Advanced Scraping first
- Monitor credit consumption for large Loop Mode batches
Timeout Configuration
Timeout Configuration
- Default 5 minutes is suitable for most use cases
- Increase for complex multi-step Web Agent workflows
- Decrease if you want faster failure detection
- Balance between reliability and execution speed
Troubleshooting
Invalid URL Error
Invalid URL Error
Problem: The node returns an “Invalid URL” errorSolution: Ensure the URL includes the protocol prefixExamples:
- ❌
www.example.com - ❌
example.com - ✅
https://www.example.com - ✅
http://www.example.com
Timeout Errors
Timeout Errors
Problem: The scrape times out before completingSolutions:
- Increase the timeout value (try 600 seconds for complex workflows)
- Verify the website is accessible from your browser
- Check if the site has slow response times
- For Web Agent mode, ensure actions aren’t waiting indefinitely
- Try enabling Advanced Scraping for better reliability
Empty or Incomplete Content
Empty or Incomplete Content
Problem: The scraped content is missing or incompleteSolutions:
- Enable “Take Action on Site?” if content loads dynamically
- Add wait actions to allow JavaScript to execute
- Enable Advanced Scraping for better content extraction
- Check if the content requires login or authentication
- Use screenshot action to visually debug what the agent sees
Access Blocked or Restricted
Access Blocked or Restricted
Problem: Website blocks or restricts accessSolutions:
- Enable Advanced Scraping for residential proxy support
- Add wait actions between interactions
- Verify the website allows automated access (check robots.txt)
- Check if the site requires authentication
- Consider whether the scraping violates terms of service
Web Agent Actions Not Working
Web Agent Actions Not Working
Problem: Actions fail to complete or produce expected resultsSolutions:
- Add wait actions after clicks to allow content to load
- Use screenshot action to debug what the agent sees
- Verify element selectors are correct
- Check if the site structure has changed
- Ensure actions are in the correct sequence
- End with a scrape or get URL action to capture output
Loop Mode Failures
Loop Mode Failures
Problem: Some URLs fail and affect the entire batchSolutions:
- Wrap Website Scraper in Error Shield node
- Test individual problematic URLs separately
- Filter invalid URLs before processing
- Check concurrency limits for your plan
- Review workflow history to identify failure patterns
Note about Web Agent Scraper: This standalone node has been merged into Website Scraper. Enable “Take Action on Site?” to access the same functionality at the same 10-credit cost.