Overview
Standard Reading
Extract text directly from PDFs at no additional cost
Advanced Reading
AI-powered structured extraction optimized for LLM processing
OCR Mode
Read scanned documents and image-based PDFs with AI vision
Reading Modes
Choose the right reading mode based on your PDF type and use case:- Standard
- Advanced
- OCR
Best for: Text-based PDFs with selectable text
- Uses direct text extraction
- Fastest processing speed
- Cost: 0 additional credits
- Limitations: Cannot read scanned images or handwritten content
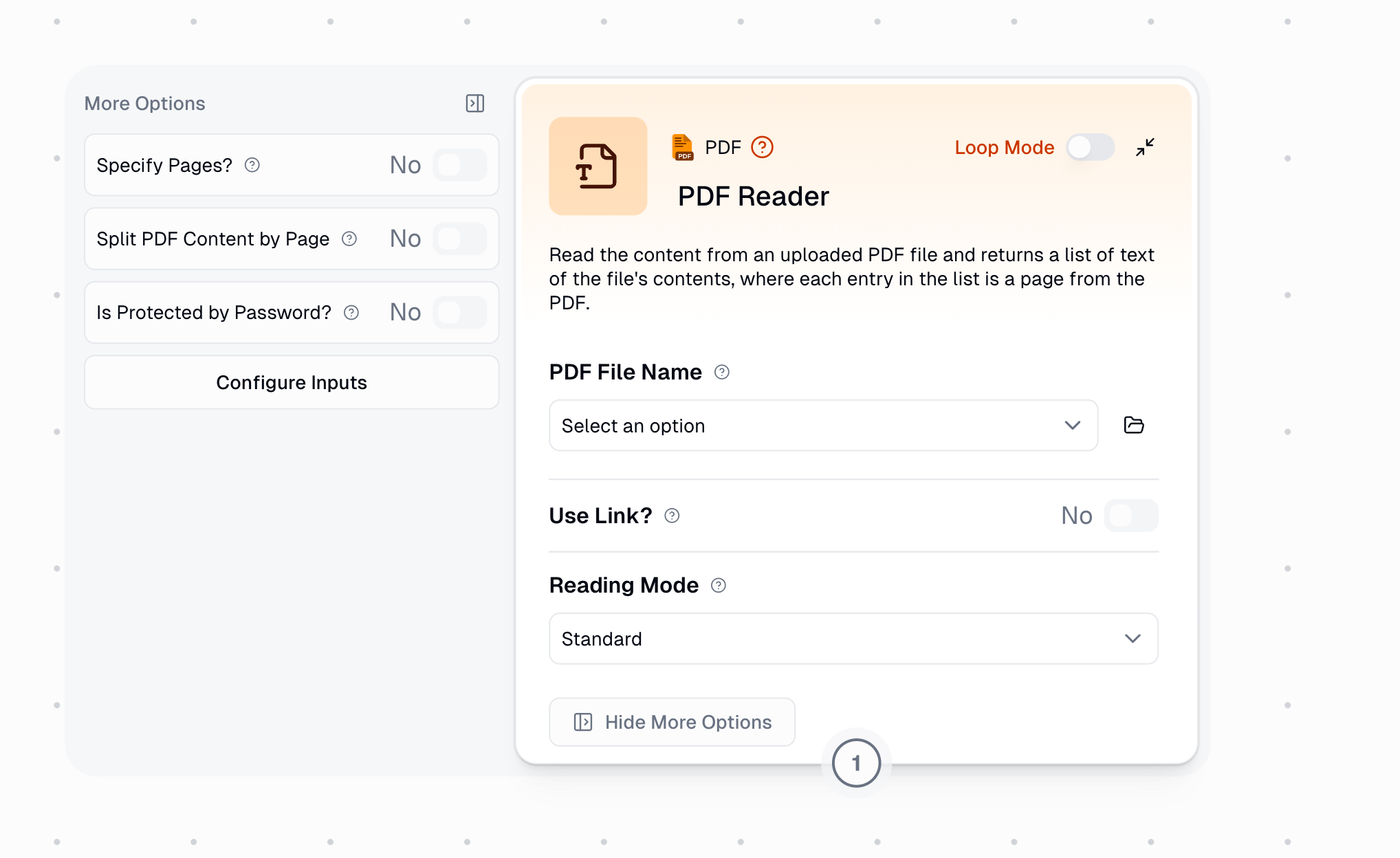
Configuration
Required Inputs
The PDF file to extract text from. This is a file picker that allows you to:
- Upload a new file directly
- Select an existing file from storage
- Dynamically pass in a file from other nodes (like Google Drive)
Only shown when “Use Link?” is disabled. Accepts
.pdf files only.Dynamic File Input
To pass PDF files dynamically from other nodes (such as files retrieved from Google Drive):1
Enable Dynamic Input
Hover over the PDF Reader node and click “Configure inputs”
2
Activate PDF File Name
In the configuration panel, enable “PDF File Name” as a dynamic input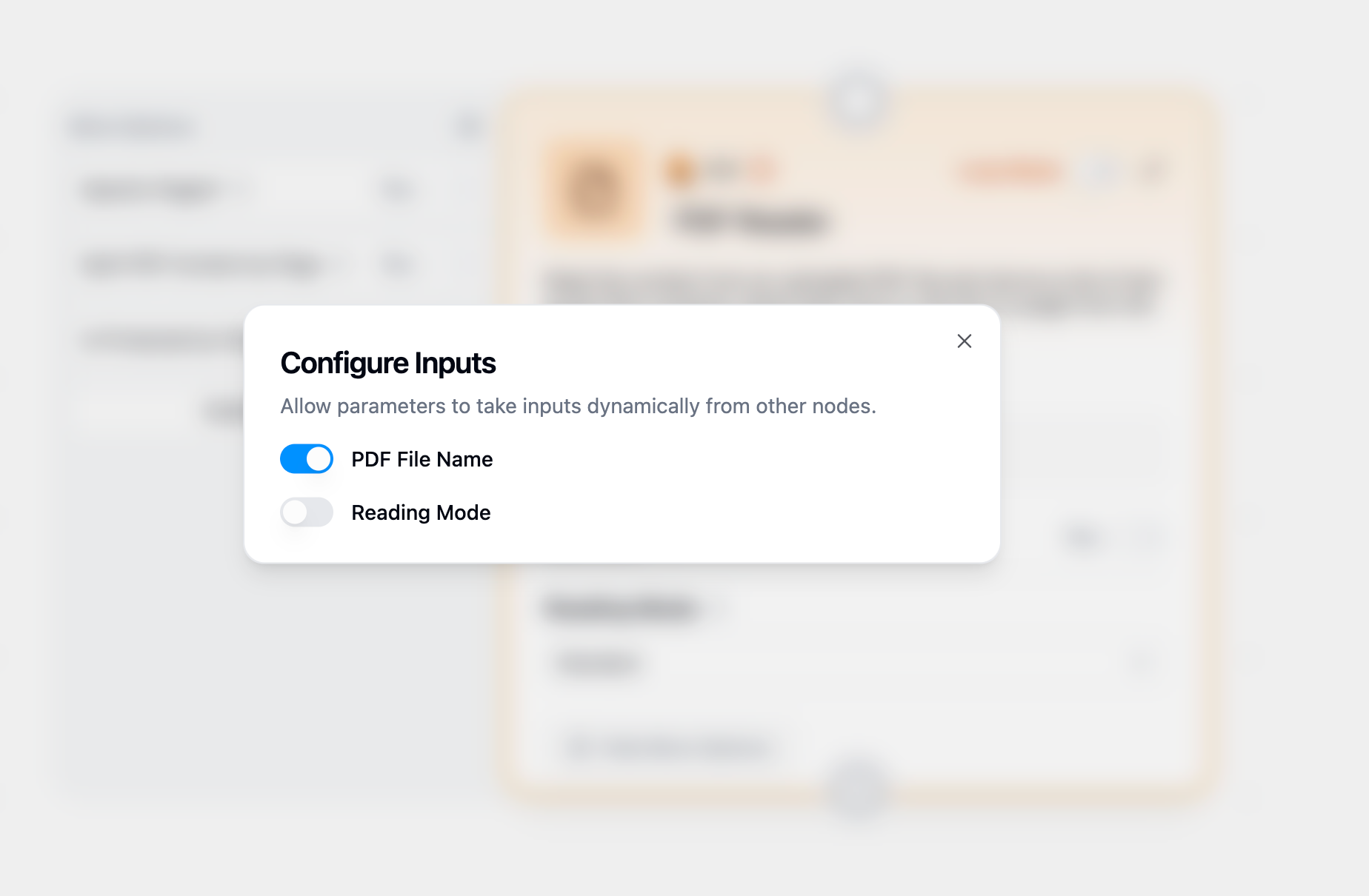
3
Connect File Source
Connect the file output from another node (like Google Drive File Reader) to the PDF File Name input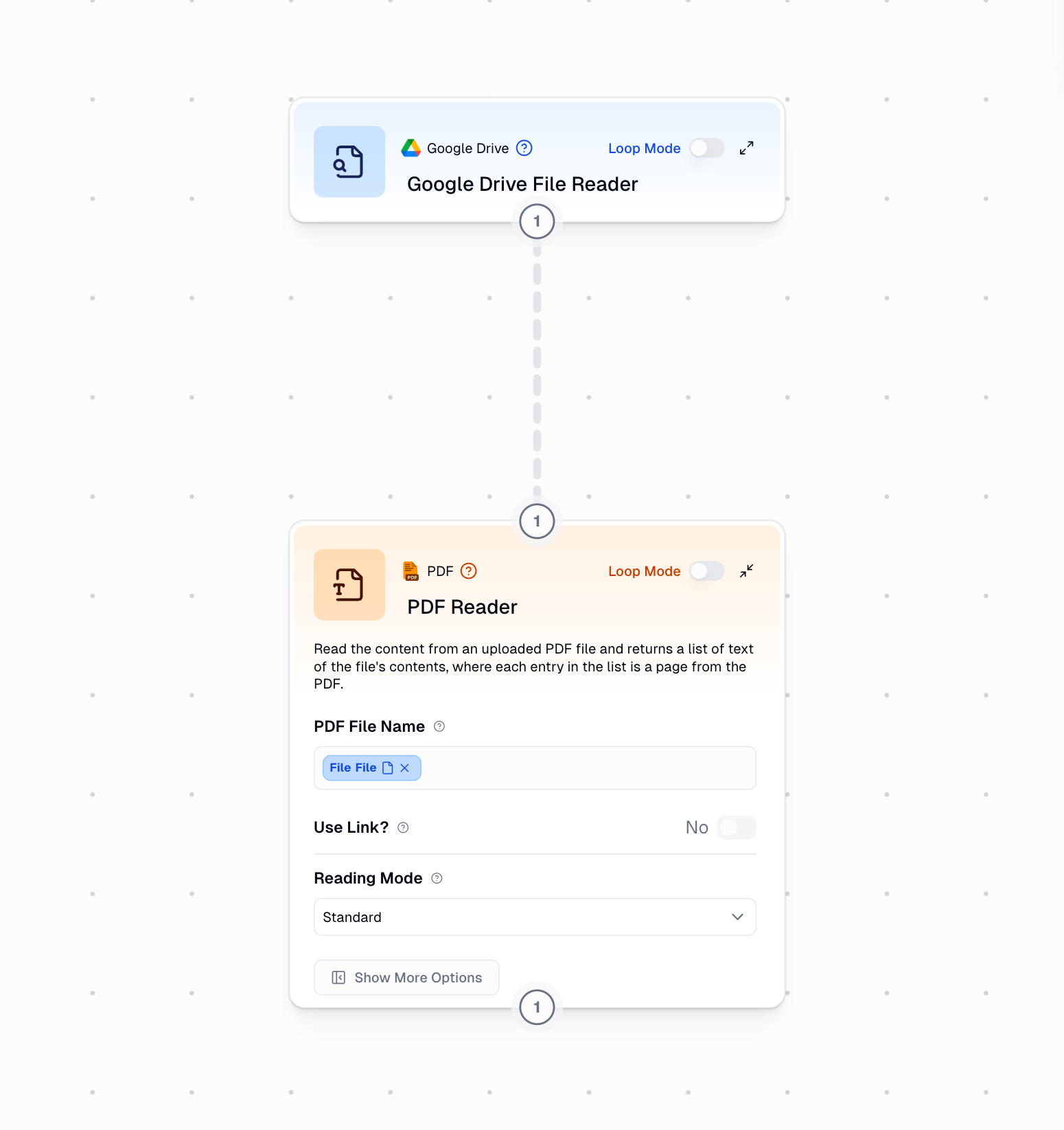
Optional Settings
Source Options
Source Options
Reading Configuration
Reading Configuration
Choose how the PDF should be processed:
- Standard: Direct text extraction (0 credits)
- Advanced: AI-powered structured reading (+5 credits)
- OCR: Optical character recognition (cost varies by model)
Enable to read only specific pages instead of the entire document.
Comma-separated page numbers and ranges.Format examples:
1-5(reads pages 1 through 5)1, 3, 5(reads pages 1, 3, and 5)1-5, 8, 11-13(reads pages 1-5, 8, and 11-13)
Page numbers are 1-indexed (first page is page 1).
Output Format
Output Format
Controls how extracted text is returned:
- Enabled: Returns a list where each item is one page
- Disabled: Returns all content as a single combined text string
Output
The extracted text content from the PDF.Output type depends on configuration:
- If “Split PDF Content by Page” is enabled: Returns
string[](list of pages) - If “Split PDF Content by Page” is disabled: Returns
string(combined text)
Common Use Cases
1
Simple Document Extraction
Extract all text from a standard PDF document at no additional cost.Configuration:
- Reading Mode: Standard
- Split PDF Content by Page: Disabled
2
LLM-Optimized Processing
Process complex PDFs with tables and formatting for AI analysis.Configuration:
- Reading Mode: Advanced (+5 credits)
- Connect output to Ask AI or Extract Data nodes
3
Scanned Document Digitization
Convert scanned PDFs or image-based documents to text.Configuration:
- Reading Mode: OCR
- Choose appropriate AI model (Mini models for cost savings)
4
Page-Specific Processing
Extract and analyze specific pages from large documents.Configuration:
- Specify Pages: Enabled
- Page Numbers: “1-3, 10”
- Split PDF Content by Page: Enabled
Credit Costs
Cost optimization tips:
- Use Standard mode whenever possible to save credits
- Choose Mini models (GPT-5.4 Mini, Claude 4.5 Haiku) for OCR when quality permits
- Test with single documents before batch processing
- Use page selection to process only needed sections
Troubleshooting
Empty or partial text extraction
Empty or partial text extraction
Problem: PDF Reader returns blank text or missing contentSolutions:
- Check if PDF contains selectable text (try highlighting text in a PDF viewer)
- For scanned documents, switch to OCR mode
- For image-based PDFs, use OCR mode instead of Standard
- Verify the PDF isn’t corrupted by opening it in another application
Password-protected PDF fails to open
Password-protected PDF fails to open
Problem: Error message when trying to read a password-protected PDFSolutions:
- Enable “Is Protected by Password?” option
- Enter the correct password in the Password field
- Verify password works by testing in a PDF viewer first
- Some PDFs have restrictions on copying/extraction - OCR mode may help
URL-based PDF won't load
URL-based PDF won't load
Problem: Cannot read PDF from provided URLSolutions:
- Ensure URL points directly to a PDF file (ends in
.pdf) - Verify URL is publicly accessible (no login required)
- Check URL doesn’t expire or require authentication
- Try downloading the PDF manually to test URL validity
Processing takes too long or times out
Processing takes too long or times out
Problem: PDF processing exceeds timeout limitsSolutions:
- Use page selection to process only needed pages
- Split large documents into smaller files
- Consider using Standard mode instead of Advanced for faster processing
- For very large documents, process in batches using Loop Mode
Related Nodes
Extract Data
Pull structured information from extracted PDF text
Ask AI
Query document content with natural language questions
File Reader
Read non-PDF document formats
AI Fill PDF
Fill PDF forms with AI-generated content
Batch Processing
The PDF Reader node supports Loop Mode for processing multiple PDFs in a single workflow. Example batch workflow:- Provide a list of PDF files as input
- Enable Loop Mode on PDF Reader
- Each PDF is read and processed sequentially
- Combine node aggregates all results